In 2020 the world shut down for a little bit and everyone got new hobbies. COVID was especially nice for me because my classes went online, which is a much easier way to get through your last two semesters of labs as a Microbiology student. The fall of my senior year I had an excess of free time, brain space, and expendable income (thanks to a fruitful summer of running one of the only open restaurants in Arlington, VA). So when some friends reached out to see if I’d be interested in playing World of Warcraft with them I figured it was a convenient way to kill time.
Plot twist: I’ve logged in to that video game every damn week since.
When I first started raiding I was introduced to a website calld “Warcraft Logs”. It’s a massive data analytics dashboard that let’s players link the combat log, a tracking log built into the game that shows every combat-related event that occurs, and analyze time series information to improve their performance. I fell madly in love with the process of looking through the website, analyzing data, and making conclusions. I’ve spent more time pouring through Warcraft Logs than I’ve spent playing the actual game.
I’m telling this story because it’s legitimately the origin of my career in statistics. Had it not been for picking up World of Warcraft as a winter COVID hobby, I wouldn’t have become a statistician.
Ever since I started studying the formal science of statistics I’ve become completely disillusioned to Warcraft Logs (shorthand WCL). The website is an incredible and accessible tool for most people. For true statistical inference though it’s a solid 3/10 product. The best thing about WCL is that it aggregates the data from the combat log— beyond that it’s a bit terrible for my purposes.
For a while now I’ve been wanting to pull data from WCL to develop some real models and metrics that we (the community) can use. Even some of the top groups in the game use ranking percentages, simple summary statistics, and questionable derived quantities to make bulk inference on player performance. The more scientifically minded groups go through player actions line by line to figure out what the players are do. Regardless of method used (beyond testimony from others and video evidence), nobody has ever been able to accurately predict whether a player was going to be capable or a burden. I’d like to change that.
This one is going to be particularly challenging from a ‘data science’ perspective because Warcraft logs .csv files are dirtier than the toilet seats in the singular bathroom at a college nightclub. But this is also a great chance for me to play around with some fun ideas I’ve had for (actually impactful and scientific) research that I’d never be able to test drive otherwise.
If I was laying this out in a book I would title chapter one, “Data Mining Hell”. WCL data is organized generally as:
Overall raid night
— Specific boss fights
---- Pulls (attempts) of the boss fight
------ Individual player data for that attempt
Most people reviewing logs start at the “Pulls” level, which seems like a lot of data but is actually miniscual. Each pull is a sample size of for (typically) 20 players. In order to have a chance at a useful quantity of data I need to grab the data using an API call.
Prior to this, I had no idea how to do an API call. Turns out it’s fucking awful.
I’ll spare the gruesome details on how I performed the API call. Partially out of shame for how it’s likely the worst code I’ve ever written, partially because it’s bad form to reveal the tokens and secrets involved.
The steps make it seem pretty simple though:
-
Download Postman (I’m not doing this with curl, no shot)
-
Set up a client through WCL
-
Use my client ID and secret to get an access token
-
Access a specific guilds log reports
-
Choose a log report
a. Get every pull of every boss from the report
b. Organize it by damage taken and done, deaths, and healing done
c. Shove it all into a JSON file
In this case I chose the guild “All Washed Up”, a US region guild on the server Sargeras. The friends who first introduced me to WCL are raiding in that guild and one of them is doing their analytics by hand. It felt like a good opportunity to test drive some of my ideas and have someone ready to proof check.
I know my query was bad because the data is still horrendously messy. That said I’m confident it’s going to take less time to clean messy JSON files than it would to learn to write better queries. Here goes nothing.
I’ve never worked with unstructured data before. As it turns out it’s not fun. Like I said, the data is shoved into one monolithic JSON file. The file contains 32 separate pulls from two bosses so for each player I should have . I converted the JSON into a huge nested list using jsonlite in R:
library(jsonlite)j = fromJSON('data/AWU_log1.json', simplifyVector = FALSE)The list is organized by damage taken, damage done, deaths, and healing done, for each pull. Since they’re in that specific order I decided to separate them with a set of simple loops. Sometimes the lazy code is the best option (this is gets worse the more I look at it):
# the first two layers of the list aren't neededreports = j$data$reportData$report
# empty lists to hold separated datadt = list() # damage takende = list() # deathshe = list() # healing donedd = list() # damage done
# indices for pulling data from the listdt_index = seq(1,length(reports),4)de_index = seq(2,length(reports),4)he_index = seq(3,length(reports),4)dd_index = seq(4,length(reports),4)
# for loops across the number of pullsfor(i in 1:32){
# use the indicies to fill each list ## with the corresponsing data dt[[i]] = reports[[dt_index[i]]][[1]] de[[i]] = reports[[de_index[i]]][[1]] he[[i]] = reports[[he_index[i]]][[1]] dd[[i]] = reports[[dd_index[i]]][[1]]
# rename everything to the appropriate pull/parameter names(dt)[i] = names(reports[dt_index[i]]) names(de)[i] = names(reports[de_index[i]]) names(he)[i] = names(reports[he_index[i]]) names(dd)[i] = names(reports[dd_index[i]])
}This leaves me with 4 lists with 32 elements corresponding to each pull. Now I’d like to organize the data in each of the 4 lists by individual data. I had to resort to using tidyverse (disgusting) to accomplish this just because base R was rapidly becoming impossible to troubleshoot.
As a rule I try to avoid tidyverse, I’m viciously against the fact that tidyverse documentation is primarily external to the CRAN documentation system. The problem is that tidyverse is really good at what it does and stackoverflow is a wealth of knowledge on pre-built functions. This particular problem was easily solved with some scrubbing through that very website.
library(purrr)library(dplyr)
# i'm in my 'obsessed with user-defined function' eraparse_entries = function(data) {
# build a loopup for each raider name per entry maps = map(data, ~{ entries = .x$entries set_names(entries, map_chr(entries, "name")) })
# retain unique raider names names_key = sort(unique(unlist(map(maps, names))))
# compile the data for each raider within the list output = map(names_key, function(name) { map(maps, ~ if (!is.null(.x[[name]])) .x[[name]] else NA) })
# rename the output to appropriate raider names names(output) = names_key
# output is a nested list with each raider ## and the pulls each raider was involved in ### if a value is NA the raider didn't participate in that pull #### or something went wrong return(output)}
# build the raider filesraiders_dt = parse_entries(dt)raiders_he = parse_entries(he)raiders_dd = parse_entries(dd)raiders_de = parse_entries(de)The data isn’t perfect right now, but it’s good enough to begin an exploratory analysis. A lot of how research works is just fumbling around until something happens, and exploratory analysis is the best way to do that as a statistician.
I think the simplest avenue of attack is a sort of “time series” of two measurements. The first I’d like to look at the proportion of damage that each player prevents relative to the amount they take:
The second I’d like to convert their damage reduction into a -score and visualize that pull-to-pull:
I wrote another UDF (shocking, I know) to pull the damage taken total and reduced. It’s not perfectly generalized but it shouldn’t be hard to generalize it later.
parse_raiders = function(data,param) {
# build the output matrix output = matrix(NA, length(data), 32) rownames(output) = names(data) # rows are raiders colnames(output) = seq(1, 32, 1) # columns are pulls
# for loops across the list for(i in 1:length(data)) {
# empty vector for raider data raider_vec = c() # temporary list of the ith raider ## i do this a lot in my list parsing ### it's easier to troubleshoot #### for larger functions that need optimization ##### i get rid of this intermediate step raider = data[[i]]
# for loop across the temporary raider list for(j in 1:length(raider)) {
# fill the vector with raider data raider_vec[j] = tryCatch(raider[[j]][[param]], error = function(e) NA)
}
# fill the matrix output[i,] = raider_vec
}
# output is a matrix of dimensions ## raiders x pulls return(output)
}
# total damage taken matrixtot_dt = parse_raiders(raiders_dt,7)# total damage reduced matrixtot_dr = parse_raiders(raiders_dt,8)
# get rid of NA rows (for now)clean_tot_dt = na.omit(tot_dt)clean_tot_dr = na.omit(tot_dr)
# calculate p_D## illegal matrix algebra, but it works in Rp_D = clean_tot_dr / clean_tot_dt
# z-scores of damage reduced## once again, very illegal matrix algebraz_Dr = (clean_tot_dr - mean(clean_tot_dr)) / sd(clean_tot_dr)Now I need to visualize these. It took a while to figure this one out but I think I’ve developed something mildly useful.
Raider performance tends to change over a long night of pulls. It’s a logical concept, a lot can change mentally over the course of 2-4 hours with maybe a 10 minute break halfway through. Quantifying raider consistency over time is usually a qualitative matter— officers (people in charge of the team) tend to go off of anecdote and “feeling” on how better or worse they think a raider gets over time.
With the measurement I can hopefully fix that. I’ll fit every raider value to a simple linear model using the pull count as a predictor, sort of substituting for discrete time steps.
Then I’ll grab the confidence interval for each parameter estimate and visualize all of that on a dot plot for each parameter across all raiders.
library(latex2exp) # ill need this to avoid learning expression()
# of course it's a UDFE_def_plots = function(data,param) { # number of pulls as t x = 1:ncol(data) # names for x axis labels raider_names = rownames(data)
# empty vectors mle = c() # beta lci = c() # lower ci of beta uci = c() # upper ci of beta
# for loop across the raiders for (i in seq_len(nrow(data))) { # simple linear regression for data and pulls m = lm(data[i,] ~ x) # confidence interval based on parameter ## 1 = b0, 2 = b1 ci = confint(m, param, 0.95) # maximum likelihood estimate of parameter mle[i] = coef(m)[param] lci[i] = ci[1] # lower bound uci[i] = ci[2] # upper bound }
# build the dot plot + error bars for each mle if (param == 1) { # ifelse for y axis label # beta 0 plot(seq_along(mle), mle, ylim = range(c(lci, uci)), xaxt = "n", xlab = "", ylab = TeX("$\\beta_0$"), type = "n")
}
else { # beta 1 plot(seq_along(mle), mle, ylim = range(c(lci, uci)), xaxt = "n", xlab = "", ylab = TeX("$\\beta_1$"), type = "n")
} # line at 0, the "ideal" raider for b1 abline(h = 0, lty = 3, lwd = 2, col = "grey80") # line at the average for the raid abline(h = mean(mle), lty = 2, lwd = 2, col = "gold") # points (to fix layering) points(seq_along(mle), mle, pch = 16) # raider names on the x axis axis(1, seq_along(raider_names), raider_names, las = 2, cex.axis = 0.7) # error bars arrows(seq_along(mle), lci, seq_along(mle), uci, angle = 90, code = 3, length = 0.05)}
plts1 = E_def_plots(p_D,1)plts2 = E_def_plots(p_D,2)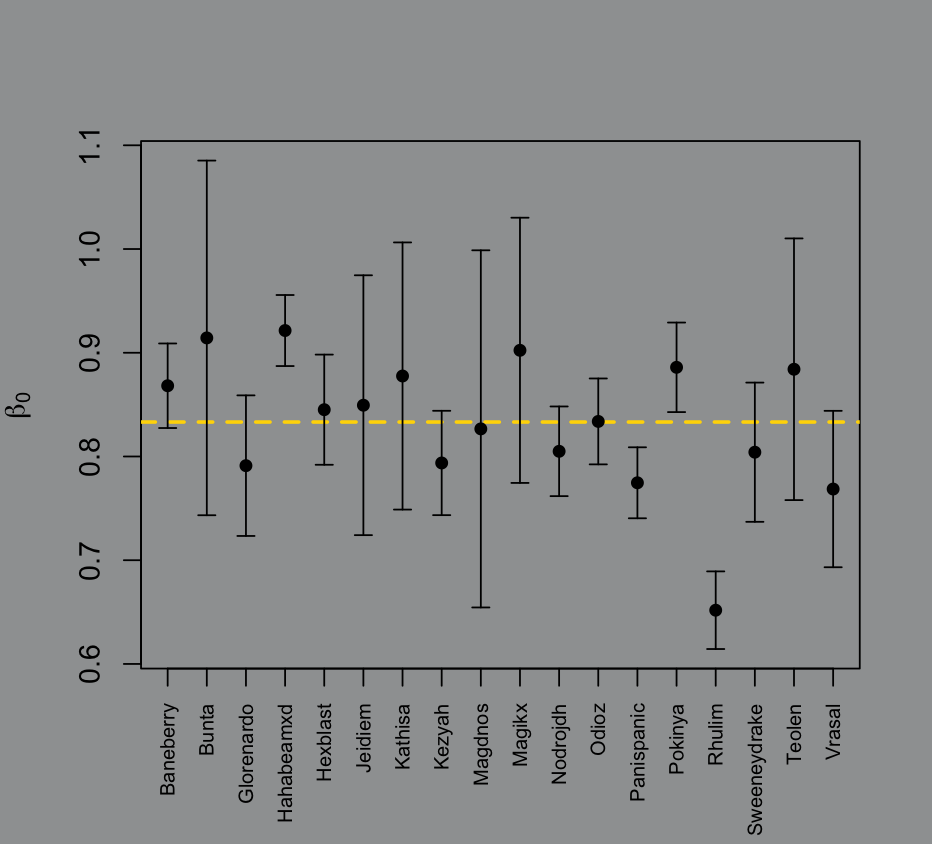
exists but in this context I don’t think it really means much. It’s the baseline of the raider’s damage prevention at pull 0, which is a little silly, but maybe someone else can extract some value from it.
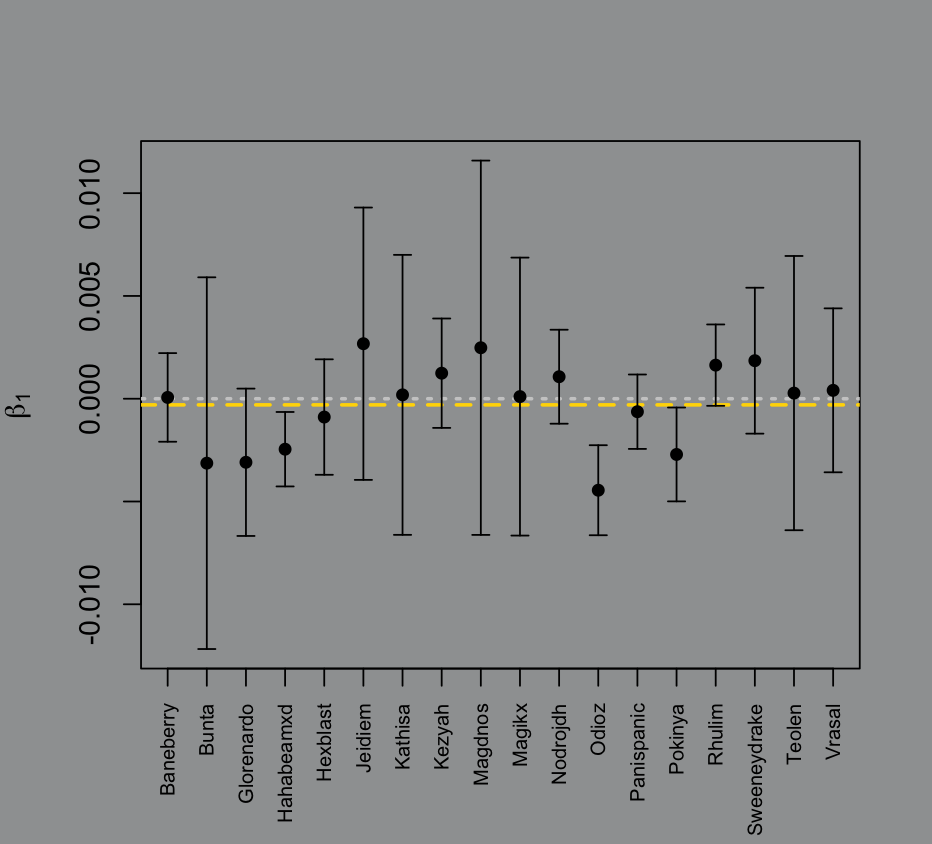
is far more interesting. It’s the trend in raider performance over every pull. A raider who gets worse over time has a negative . If it’s positive they get better over time. The larger the confidence bands the more variation in their performance. So the “ideal” raider would have a with no confidence bands; they’re perfectly consistent from beginning to end.
The way that I calculated the -scores for damage reduced used the global mean and standard deviation for the raid across all pulls. That’s probably not the best measurement since some roles and classes will always take and reduce higher magnitudes of damage.
I took the mean of each raider’s -score and plotted it on a scatter plot:
# raider average z-score of damage reducedz_Dr_bar = rowMeans(z_Dr)
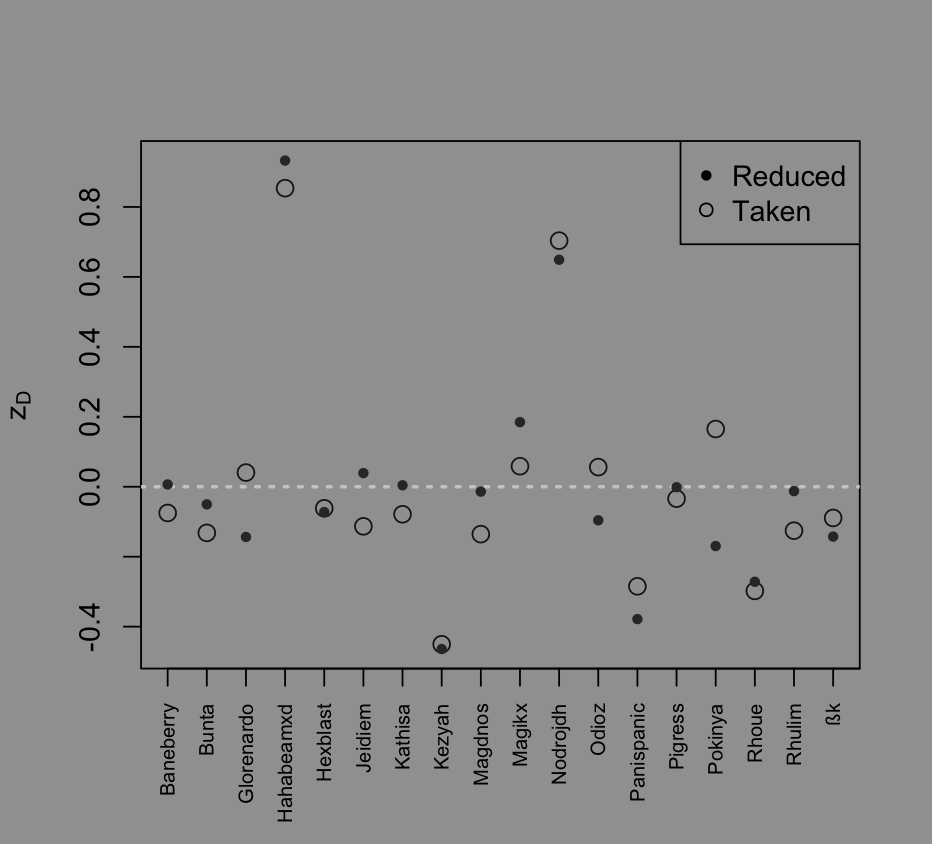
# plot of those z-scores per raiderplot(seq_along(z_Dr_bar),z_Dr_bar, xaxt = "n", xlab = "", ylab = TeX("$z_{Dr}$"), type = "n")# 0 line for referenceabline(h = 0, lty = 3, lwd = 2, col = "grey80")# points layerpoints(seq_along(z_Dr_bar), z_Dr_bar, pch = 16)# raider names of the x axisaxis(1, seq_along(rownames(tot_dr)), rownames(tot_dr), las = 2, cex.axis = 0.7)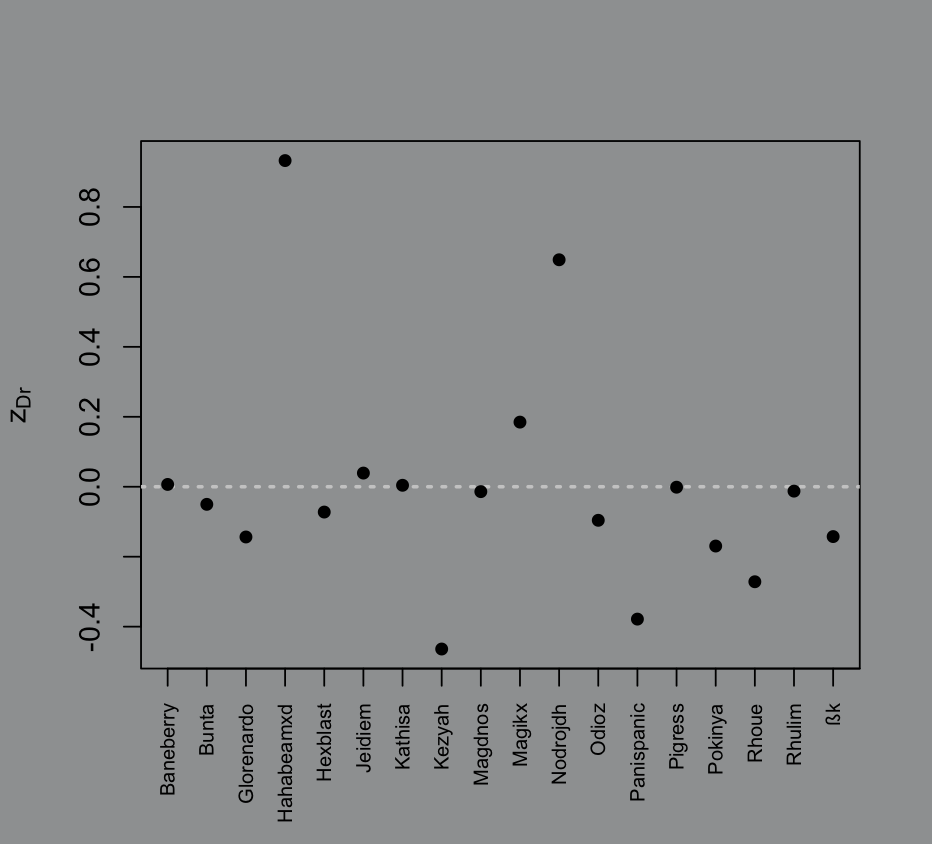
Computing a -score is typically referred to as “standardizing the data” because it converts data into a standard normal distribution (given that the data was already normal).
Hypothetically, every raider should have a mean -score of . If someone has a higher score than they’re typically reducing more damage than the rest of the raid, vice versa if they have a lower score.
Again, this measurement isn’t the best because its basis is flawed. I also can’t work with a -score for proportions because the denominator doesn’t play nice, so we’re stuck with the general issues of this metric. What I can do instead is calculate each set of -scores for damage reduced and damage taken, then plot both values on a scatterplot. I’ll make the points for damage taken hollow and keep the points for damage reduced as is to avoid missing an overlap. Hopefully that gives more context to certain points being very high or very low.
# raider average z-score of damage takenz_Dt_bar = rowMeans(z_Dt)
par(bg="#9EA0A1")# plot of those z-scores per raiderplot(seq_along(z_Dt_bar),z_Dt_bar, ylim = c(min(z_Dr_bar,z_Dt_bar),max(z_Dr_bar,z_Dt_bar)), xaxt = "n", xlab = "", ylab = TeX("$z_{Dt}$"), type = "n")# 0 line for referenceabline(h = 0, lty = 3, lwd = 2, col = "grey80")# points layer, open circle for damage taken, closed for reducedpoints(seq_along(z_Dt_bar), z_Dt_bar, cex = 1.3, col = "grey10")points(seq_along(z_Dr_bar), z_Dr_bar, pch = 20, cex = 1, col = "grey20")# raider names of the x axisaxis(1, seq_along(rownames(tot_dt)), rownames(tot_dt), las = 2, cex.axis = 0.7)legend("topright", inset = c(0,0), legend = c("Reduced","Taken"), pch = c(20,1), title = "Damage")